Relational database design and organisation are based on the fundamental idea of database normalisation. Enhancing data integrity, lowering redundancy, and enabling effective data management are its main objectives. We will delve into the fundamentals of database normalisation, examine the normalisation procedure, talk about different forms and techniques of normalisation, and look at the function of denormalization in this extensive guide.
1. What is Database Normalization?
The process of arranging data in a relational database to reduce dependencies and redundancies is called database normalisation. It entails defining relationships between big tables and segmenting them into smaller, easier-to-manage entities. Eliminating data anomalies, preserving data integrity, and improving database performance are the main goals of normalisation.
Normalisation forms are a collection of guidelines and norms that serve as the foundation for database normalisation. These forms offer an organised method for arranging data and enhancing database performance. A well-organized and normalised data model that facilitates effective data storage, retrieval, and manipulation can be achieved by databases by following the normalisation principles.
2. The Normalization Process
The normalization process typically involves several stages, each focusing on a specific aspect of data organization and structure. These stages are represented by normalization forms, which define progressively stricter rules for data organization.
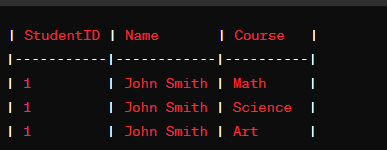
First Normal Form (1NF): The first normal form requires that each table cell contains a single value, and there are no repeating groups or arrays of data within a row. To achieve 1NF, tables are divided into rows and columns, and atomic values are ensured for each attribute.
Example:
Consider a table for storing student information:
To convert this table to 1NF, we break the Courses column into atomic values:
|
Second Normal Form (2NF): The second normal form builds upon the first by eliminating partial dependencies. It requires that each non-key attribute is fully functionally dependent on the primary key. This is achieved by breaking down tables into smaller entities and ensuring that each attribute depends on the entire primary key, not just part of it.
Example:
Consider a table for storing orders and products:
To convert this table to 2NF, we break it into two tables: Orders and Products, with the primary key of Orders being OrderID and the primary key of Products being ProductID. We then remove redundant information from the Orders table:
Third Normal Form (3NF): The third normal form further refines the data structure by eliminating transitive dependencies. It requires that each non-key attribute is functionally dependent only on the primary key and not on other non-key attributes. This is accomplished by removing attributes that depend on other non-key attributes.
Example:
Consider a table for storing employee information:
Jane Doe |
To convert this table to 3NF, we remove the ManagerName attribute, as it is functionally dependent on ManagerID:
We then create a separate table for managers:
Jane Doe |
Boyce-Codd Normal Form (BCNF): BCNF is a stricter form of normalization that eliminates all non-trivial functional dependencies. It ensures that every determinant is a candidate key, thereby minimizing redundancy and dependency. Achieving BCNF may require decomposing tables into smaller entities and redefining relationships.
3. Functional Dependencies and Normalization Forms
Functional dependencies play a crucial role in the normalization process by defining the relationships between attributes in a table. A functional dependency exists when one attribute uniquely determines another attribute. By identifying and eliminating dependencies, databases can achieve higher levels of normalization and reduce data redundancy.
Normalization forms are based on specific rules and criteria for functional dependencies. Each normalization form addresses different types of dependencies and anomalies, guiding database designers in the process of organizing data effectively.
4. Common Normalization Techniques
While the normalization process aims to optimize database structure and integrity, it may sometimes lead to performance implications, such as increased join operations and query complexity. In such cases, denormalization techniques may be employed to balance performance and maintainability.
Denormalization: Denormalization involves reintroducing redundancy into a normalized database to improve query performance and simplify data retrieval. This may include duplicating data, introducing redundant indexes, or precalculating summary statistics. Denormalization should be approached cautiously to avoid compromising data integrity and consistency.
Partial Denormalization: Partial denormalization selectively introduces redundancy into specific areas of a database where performance improvements are most needed. This approach allows for a balance between normalization principles and performance considerations, providing flexibility in database design.
Horizontal and Vertical Denormalization: Horizontal denormalization involves splitting a table into multiple smaller tables to reduce data redundancy and improve performance. Vertical denormalization, on the other hand, involves combining multiple tables into a single table to simplify queries and reduce join operations.
5. Conclusion
A crucial component of relational database architecture, database normalisation seeks to reduce redundancy, enhance data integrity, and maximise database performance. Databases can create an effective and well-organized data model that satisfies the needs of contemporary applications by following normalisation forms and principles.
To sum up, building reliable and scalable databases requires an awareness of functional interdependence, database normalisation, and normalisation forms. Normalisation guarantees data organisation and integrity; performance concerns can be addressed by using denormalization techniques. Organisations may create robust, high-performance database systems that serve their business goals by finding a balance between normalisation and denormalization.
Significant breakthroughs, inventions, and paradigm shifts have all occurred during the intriguing journey that has been the evolution of database management systems (DBMS). Organisations’ approaches to managing and using their data have changed dramatically as a result of the development of database management systems (DBMSs), which started out small with early file-based systems and progressed to powerful relational databases, NoSQL, and distributed databases. We will examine the history of database management systems (DBMS) in this extensive guide, covering their inception, significant turning points, and important advancements that have impacted the field of contemporary data management.
1. Origins of Database Management Systems
Businesses and organisations started to recognise the need for effective data management solutions in the 1960s, which is when DBMS first emerged. Data was stored and retrieved using flat files in the earliest database systems, sometimes referred to as file-based systems. These systems lacked the scalability and flexibility needed to adapt to the changing needs of organisations. They were also outdated and inflexible.
Key Milestones: The introduction of hierarchical and network database models in the 1960s and 1970s marked significant milestones in the evolution of DBMS. These models provided hierarchical and networked structures for organizing and accessing data, laying the foundation for more sophisticated database technologies.
Hierarchical Model: In the hierarchical model, data is organized in a tree-like structure with parent-child relationships between records. This model was popularized by IBM’s Information Management System (IMS) and provided efficient access to hierarchical data structures such as organizational charts and bill of materials.
Network Model: The network model introduced the concept of sets and relationships between records, allowing for more complex data structures. This model was implemented in database systems such as CODASYL (Conference on Data Systems Languages) and provided greater flexibility for representing interconnected data.
2. Rise of Relational Databases
The 1970s witnessed a revolutionary breakthrough with the development of relational database management systems (RDBMS), pioneered by Edgar F. Codd. Tables, rows, and columns were first introduced by relational databases, along with the structured query language (SQL) that allows for data manipulation and querying.
Key Innovations: The relational model offered several key innovations, including data independence, declarative query language, and support for ACID transactions. These features made relational databases more flexible, scalable, and suitable for a wide range of applications across various industries.
Relational Algebra: Codd’s relational algebra provided a theoretical foundation for relational databases, defining operations such as selection, projection, join, and union. This algebraic framework enabled developers to perform complex data manipulations using simple, declarative queries.
3. Emergence of NoSQL Databases
The advent of NoSQL (Not Only SQL) databases in the early 2000s was caused by the exponential growth of data in the digital age and the demand for scalable, high-performance data storage solutions. NoSQL databases provided options for a variety of data types, volumes, and processing needs, providing an alternative to conventional relational databases.
Types of NoSQL Databases: NoSQL databases encompass various types, including document-oriented, key-value, column-family, and graph databases. Each type is optimized for specific use cases, such as flexible data modeling, distributed architectures, and high availability.
Document-Oriented Databases: Document-oriented databases, such as MongoDB and Couchbase, store data in flexible, schema-less documents, typically in JSON or BSON format. These databases are well-suited for handling semi-structured data and use cases such as content management, user profiles, and product catalogs.
Key-Value Stores: Key-value stores, such as Redis and Amazon DynamoDB, store data as key-value pairs and offer fast, scalable access to frequently accessed data. These databases are ideal for caching, session management, and real-time analytics applications.
4. Evolution of Distributed Databases
Distributed databases, which span multiple nodes, regions, or data centres, are an evolution of distributed systems driven by the proliferation of big data, cloud computing, and distributed systems. Organisations are able to process and analyse enormous volumes of data across distributed environments thanks to distributed databases’ scalability, fault tolerance, and global availability.
Types of Distributed Databases: Distributed databases come in various forms, including sharded databases, replicated databases, and multi-model databases. These databases leverage distributed architectures, replication techniques, and consensus algorithms to ensure data consistency and availability.
Sharded Databases: Sharding involves partitioning data into smaller, manageable chunks called shards and distributing them across multiple nodes or clusters. Each shard operates independently, enabling horizontal scaling and improved performance. Sharded databases, such as Google Bigtable and Apache Cassandra, are well-suited for handling massive datasets and high throughput workloads.
Replicated Databases: Replication involves maintaining copies of data across multiple nodes or data centers to ensure data availability and fault tolerance. Replicated databases, such as Apache HBase and Amazon Aurora, use techniques such as master-slave replication and multi-master replication to synchronize data across replicas and handle failover scenarios.
5. Future Trends and Innovations
In the future, developments in blockchain databases, in-memory databases, and federated databases are expected to propel the development of database management systems (DBMS). Blockchain databases are perfect for applications that need security, trust, and transparency because they provide decentralised, immutable, and transparent data storage.
In-memory Databases: In-memory databases leverage main memory for storing and processing data, delivering ultra-fast performance and real-time analytics. These databases are well-suited for high-speed transaction processing, real-time data warehousing, and analytics applications.
Federated Databases: Federated databases enable seamless integration and querying of data across heterogeneous data sources and platforms. These databases leverage distributed query processing, data virtualization, and metadata management to provide a unified view of data from disparate sources.
Conclusion
From the first file-based systems to the most recent distributed databases and beyond, the evolution of database management systems (DBMS) has been marked by constant innovation. The development of DBMSs is a reflection of the dynamic nature of data management, which is shaped by changing business requirements, industry trends, and technology breakthroughs.
To sum up, the development of database management systems (DBMS) has revolutionised the way businesses store, handle, and use their data, giving them the ability to gain a competitive edge, generate new ideas, and gain insights. Organisations can leverage the power of database management systems (DBMS) to unlock new opportunities and navigate the complexities of the digital age by embracing emerging technologies, adopting best practices, and staying up to date with industry trends.
Database management systems’ (DBMS’s) capacity to grow and operate at peak efficiency is essential in today’s data-driven environment to fulfil the needs of contemporary users and applications. Scalability is the system’s ability to manage increasing workloads effectively; performance tuning, on the other hand, is the process of fine-tuning the DBMS to improve speed, responsiveness, and resource efficiency. This article will discuss methods and best practices for optimising DBMS performance and scalability so that businesses can efficiently manage their data infrastructure.
1. Horizontal and Vertical Scaling
While vertical scaling calls for improving the resources (CPU, memory, and storage) of current servers, horizontal scaling includes adding more nodes or instances to spread the burden across numerous computers. Although both strategies have advantages in terms of scalability, they differ in terms of cost, complexity, and performance.
Horizontal Scaling: Implementing horizontal scaling involves deploying database replicas or shards across multiple servers, enabling parallel processing and improved fault tolerance. This approach is well-suited for handling high volumes of read and write operations, but it may introduce complexities related to data consistency and synchronization.
Vertical Scaling: Vertical scaling involves upgrading the hardware resources of a single server to accommodate increased workloads. This approach is simpler to implement but may have limitations in terms of scalability and cost-effectiveness.
Horizontal Scaling Strategies: Organizations can achieve horizontal scaling by adopting techniques such as data partitioning, sharding, and distributed databases. These strategies allow for the distribution of data and workload across multiple nodes, enabling linear scalability and improved performance.
Vertical Scaling Best Practices: When pursuing vertical scaling, organizations should focus on optimizing hardware resources such as CPU, memory, and storage. Techniques such as database compression, query optimization, and storage optimization can help maximize the efficiency of vertical scaling efforts.
2. Indexing and Query Optimization
In order to improve database speed, efficient indexing and query optimisation are essential for reducing the amount of time and resources needed to retrieve and process data. Indexes reduce the need for full-table scans by organising and sorting data according to predefined columns, facilitating rapid data lookup.
Types of Indexes: DBMS supports various types of indexes, including primary indexes, secondary indexes, and composite indexes. Understanding the characteristics and usage scenarios of each index type is essential for optimizing query performance.
Query Optimization Techniques: Techniques such as query rewriting, join optimization, and use of appropriate execution plans help optimize query performance by reducing execution time and resource consumption. DBMS provides tools and utilities for analyzing query execution plans and identifying optimization opportunities.
Indexing Best Practices: Organizations should carefully design and maintain indexes based on query patterns, access patterns, and data distribution. Techniques such as index fragmentation analysis, index usage monitoring, and index defragmentation can help ensure optimal index performance and efficiency.
3. Caching and Data Partitioning
By lowering disc I/O and latency, caching frequently requested data in RAM can greatly enhance database performance. The speed and responsiveness of data retrieval are improved by caching techniques such application-level caching, query result caching, and in-memory databases.
Data Partitioning: Partitioning involves dividing large datasets into smaller, manageable partitions based on predetermined criteria such as range, hash, or list. Partitioning distributes data across multiple storage devices or servers, enabling parallel processing and efficient data retrieval.
Sharding: Sharding is a horizontal partitioning technique that distributes data across multiple database instances or shards based on a shard key. Each shard operates independently, allowing for distributed storage and processing of data. Sharding is particularly useful for scaling out large databases and achieving high availability.
Caching Best Practices: Organizations should implement caching strategies based on the frequency of data access, data volatility, and resource availability. Techniques such as cache invalidation, cache expiration policies, and cache warming can help maximize the effectiveness of caching solutions and minimize cache-related issues.
4. Load Balancing and Database Performance Monitoring
The purpose of load balancing is to prevent individual nodes from being overloaded and to optimise resource utilisation by dividing up incoming client requests among several database servers or replicas. In order to dynamically modify traffic distribution and guarantee peak performance, load balancers keep an eye on server health and performance indicators.
Database Performance Monitoring: Continuous monitoring of database performance metrics such as CPU utilization, memory usage, disk I/O, and query execution time is essential for identifying bottlenecks, diagnosing issues, and proactively optimizing system performance. DBMS provides monitoring tools, dashboards, and alerts for real-time performance monitoring and analysis.
Load Balancing Strategies: Organizations can implement load balancing solutions such as round-robin DNS, hardware load balancers, and software load balancers to distribute incoming traffic evenly across database servers. Techniques such as session affinity and health checks help ensure efficient load balancing and fault tolerance.
Performance Monitoring Best Practices: Organizations should establish performance monitoring policies and procedures to track key performance indicators (KPIs) and metrics. Techniques such as trend analysis, anomaly detection, and capacity planning can help identify performance issues, optimize resource utilization, and improve overall system performance.
Conclusion
Database management systems (DBMS) provide essential features like scalability and performance optimisation that help businesses handle increasing amounts of data and satisfy the demands of contemporary applications. Organisations can optimise their DBMS architecture for improved scalability, responsiveness, and reliability by putting indexing, caching, data partitioning, load balancing, and performance monitoring into practice.
In summary, proactive monitoring, optimisation strategies, and architectural design must all be combined to achieve scalability and performance optimisation in DBMS. Employing cutting-edge tools and technologies along with best practices can help organisations create high-performance, resilient database systems that adapt to changing business requirements.
In the world of database management systems (DBMS), dependable transactions and data integrity are critical. This is where the features of ACID are useful. Atomicity, Consistency, Isolation, and Durability, or ACID for short, is an acronym representing a set of guidelines that control how transactions behave within a database system. We will examine each ACID attribute in detail in this extensive book, explaining its importance, how it’s implemented, and how it affects the dependability and integrity of database operations.
1. Atomicity
Atomicity refers to the indivisibility of a transaction. A transaction is considered atomic if it either executes in its entirety or not at all. In other words, it ensures that all operations within a transaction are successfully completed, or none of them are executed. This property prevents the database from being left in an inconsistent state due to partial transaction execution.
Implementation: DBMS ensures atomicity through transaction management mechanisms such as transaction logs and rollback procedures. Transaction logs record the sequence of operations performed during a transaction, enabling the system to undo changes in case of a failure. Rollback procedures revert the database to its previous state if a transaction encounters an error.
Impact: Atomicity guarantees data integrity by preserving the consistency of the database. It ensures that only valid and complete transactions are committed, preventing any intermediate states that could compromise data reliability.
Example: Consider a banking application where a transfer of funds between two accounts is initiated. The transaction involves deducting funds from one account and crediting them to another. If the transaction fails after deducting funds from one account but before crediting them to the other, atomicity ensures that the deduction is rolled back, maintaining the integrity of account balances.
2. Consistency
The maintenance of consistency guarantees that the database is still valid both before and after a transaction is completed. It basically maintains the logical correctness of data by enforcing referential integrity, integrity constraints, and business rules. Only transactions adhering to predetermined rules are permitted to make modifications to the database, as per consistency requirements.
Implementation: DBMS implements consistency through constraint enforcement mechanisms, such as primary key constraints, foreign key constraints, and check constraints. These constraints define the permissible state transitions and data modifications, ensuring that the database remains consistent at all times.
Impact: Consistency guarantees the reliability and accuracy of data stored in the database. By enforcing integrity constraints and business rules, it prevents unauthorized or erroneous transactions from corrupting the database, thereby maintaining data quality and trustworthiness.
Example: In an e-commerce application, consistency ensures that the quantity of available products is updated correctly when a purchase transaction is made. If a customer attempts to buy more items than are available in stock, the transaction is rejected to maintain consistency between the displayed inventory and the actual stock levels.
3. Isolation
In a multi-user environment, isolation pertains to the simultaneous execution of transactions. It guarantees that a transaction’s result is unaffected by other concurrent transactions that are being carried out simultaneously. By isolating data, concurrent access to shared data reduces the possibility of interference, conflicts, and anomalies.
Implementation: DBMS employs concurrency control mechanisms such as locking, multiversion concurrency control (MVCC), and transaction isolation levels (e.g., Read Committed, Repeatable Read, Serializable) to achieve isolation. Locking mechanisms restrict access to shared resources, ensuring that transactions execute in isolation without interference from others.
Impact: Isolation maintains the consistency and correctness of transactions by preventing concurrency-related issues such as dirty reads, non-repeatable reads, and phantom reads. It ensures that each transaction sees a consistent snapshot of the database, regardless of concurrent modifications by other transactions.
Example: Consider a reservation system for booking airline seats. If two users simultaneously attempt to book the same seat, isolation ensures that only one transaction succeeds while the other is blocked or rolled back to prevent double booking and maintain data consistency.
4. Durability
Even in the case of system malfunctions or crashes, durability ensures that committed transactions will remain intact. When a transaction is successfully committed, its consequences are retained in the database indefinitely and are not lost as a result of system malfunctions. The ability of the database to bounce back from errors without sacrificing consistency or integrity of data is known as durability.
Implementation: DBMS achieves durability through transaction logging and write-ahead logging (WAL) techniques. Transaction logs record committed transactions and their corresponding changes to the database, allowing the system to replay and recover transactions in case of failures.
Impact: Durability ensures data persistence and reliability by safeguarding committed transactions against system failures. It provides users with confidence that their data will remain intact and recoverable, even in the face of unexpected events.
Example: In a social media platform, when a user posts a message, durability ensures that the post is permanently stored in the database, even if the system experiences a crash immediately after the post is made. Users can rely on the platform to retain their data reliably over time.
Conclusion
In Database Management Systems (DBMS), the ACID properties serve as the fundamental basis for transaction management. By following these guidelines, database management systems (DBMS) guarantee data consistency, reliability, and integrity, enabling stable and reliable database operations. Completeness of transactions is ensured by atomicity, data correctness is enforced by consistency, concurrency anomalies are prevented by isolation, and data persistence is guaranteed by durability. These characteristics support the integrity and dependability of a database system by laying the groundwork for a solid and reliable system.
Finally, in order to create and maintain robust and dependable database systems that satisfy the demanding needs of contemporary applications and enterprises, it is imperative to comprehend and put into practice the ACID properties.
Application Programming Interfaces, or APIs, are essential for facilitating communication between various services and applications in the dynamic field of web development. But a crucial choice must be made when creating an API: do you use an RPC-based or RESTful approach? There are clear benefits and drawbacks to each method, and the best decision will depend on the particulars of your project. This article explores the fundamental ideas, benefits, and drawbacks of RESTful and RPC APIs, enabling you to choose wisely for your upcoming project.
Demystifying RESTful APIs: Simplicity and Web-Friendliness
Using the fundamental ideas of the web, REST (Representational State Transfer) is an architectural methodology for creating APIs. It places a strong emphasis on a stateless client-server architecture in which every request made by an application to a server—the service provider—is handled as a separate transaction. RESTful APIs are renowned for their:
Simplicity: REST adheres to a set of well-defined design principles, making it easy to understand and implement for developers.
Standardized Communication: RESTful APIs utilize HTTP verbs (GET, POST, PUT, DELETE) to represent CRUD (Create, Read, Update, Delete) operations on resources. This standardization fosters interoperability between different applications and platforms.
Statelessness: Each request in a RESTful API carries all the necessary information for the server to process it. The server doesn’t maintain any session state between requests, simplifying scalability and reliability.
Resource-Oriented Design: RESTful APIs treat data as resources identified by URIs (Uniform Resource Identifiers). This approach aligns well with web browsing paradigms, making it intuitive for developers familiar with the web.
Flexibility: RESTful APIs are not restricted to a single data format. You can employ JSON, XML, or even custom formats to represent data, catering to diverse client application needs.
Cachability: Responses from RESTful APIs can be cached by intermediaries (like web caches), leading to improved performance and reduced server load.
These advantages make RESTful APIs the de facto standard for building web-based APIs. Their simplicity, interoperability, and ease of use contribute significantly to their widespread adoption.
However, RESTfulness comes with its own set of limitations:
Verbosity: For complex operations involving multiple resources, RESTful APIs can require a series of requests, potentially leading to verbose communication.
Limited Functionality: While ideal for CRUD operations, REST may not be as efficient for complex function calls requiring intricate arguments and return values.
Discovery Challenges: While standardized, discovering all available resources and their corresponding operations within a large RESTful API can be cumbersome.
Unveiling RPC APIs: Efficiency for Platform-Specific Interactions
RPC (Remote Procedure Call) is a different approach to API design. It focuses on mimicking local procedure calls within an application, but across a distributed network. Here’s what defines RPC APIs:
Platform-Specific: RPC APIs are often tied to specific programming languages or platforms, leading to tighter integration and potentially improved performance. They typically use language-specific data structures for arguments and return values.
Direct Function Calls: RPC APIs resemble local function calls, allowing developers to directly invoke remote procedures on the server with specific arguments. This can be more concise for complex operations compared to making multiple RESTful requests.
State Management: RPC APIs can optionally manage state between client and server, which can be beneficial for certain use cases like maintaining user sessions or long-running processes.
These characteristics provide RPC APIs with certain advantages:
Performance: Due to their platform-specific nature and direct function calls, RPC APIs can potentially offer better performance than RESTful APIs for specific use cases.
Reduced Verbosity: Complex operations can be achieved with fewer messages compared to a RESTful approach.
Strong Typing: By leveraging language-specific data structures, RPC APIs enforce stricter type checking, potentially leading to fewer runtime errors.
However, RPC APIs also have drawbacks to consider:
Limited Interoperability: Their platform-specific nature hinders interoperability between diverse applications and platforms. Switching to a different platform might necessitate a complete rewrite of the API client.
Complexity: Designing and implementing RPC APIs can be more complex compared to RESTful APIs, especially for developers unfamiliar with the chosen platform.
Discovery and Documentation: Discovering available functions and their parameters within an RPC API can be challenging, requiring detailed documentation.
Choosing Your Weapon: When to Use REST vs. RPC
Now that you understand the core concepts and trade-offs of both approaches, here are some guiding principles to help you select the right API type for your project:
Web Integration: If your API needs to seamlessly integrate with web applications and leverage the power of the web (caching, standardized communication), a RESTful approach is the clear winner. Its simplicity and alignment with web concepts make it an ideal choice for building public APIs accessible to a broad developer audience.
Platform-Specific Communication: When dealing with tightly-coupled systems within the same platform or language environment, RPC APIs can shine. Their efficiency, strong typing, and potential performance gains make them a compelling option for internal APIs or microservices communication within a controlled ecosystem.
Data Exposure: If your API primarily focuses on CRUD operations on well-defined resources, a RESTful approach offers a clean and intuitive way to expose data. Its resource-oriented design aligns well with representing data entities and their relationships.
Complex Functionality: For APIs involving intricate function calls with complex arguments and return values, RPC can be advantageous. Its direct function call approach can streamline communication compared to breaking down operations into multiple RESTful requests.
Scalability and Maintainability: RESTful APIs often excel in terms of scalability due to their stateless nature. Each request is independent, making it easier to scale the server-side infrastructure horizontally. Additionally, their adherence to well-defined design principles generally leads to better maintainability and understandability for developers.
Discovery and Documentation: RESTful APIs, with their standardized verbs and resource-oriented structure, tend to be easier to discover and document. Tools like Swagger can readily generate interactive documentation from a well-defined RESTful API.
Security Considerations: Both RESTful and RPC APIs can be implemented securely. However, with RESTful APIs, security needs to be carefully addressed at the resource level, using mechanisms like authentication and authorization for access control. RPC APIs, due to their potential state management, might require additional security measures to prevent unauthorized access or session hijacking.
Beyond the Binary: Hybrid Approaches
The decision between REST and RPC isn’t always clear-cut in the real world. When some API functionalities are better served by a hybrid method than by a traditional one, hybrid approaches may be used. For example, an API may provide platform-specific RPC capabilities for more complex tasks, while at the same time exposing basic data resources through a RESTful interface.
Conclusion
The best API design ultimately depends on having a clear grasp of your project’s needs, target market, and desired features. You may make an informed choice that establishes the groundwork for a fruitful and seamlessly integrated development process by carefully weighing the advantages and disadvantages of RESTful and RPC APIs.
Additional Considerations
Existing Infrastructure: If you’re already heavily invested in a specific platform or programming language, an RPC API leveraging those strengths might be a more natural fit.
Team Expertise: Consider your development team’s familiarity with RESTful principles or RPC frameworks. Choosing an approach that aligns with their skillset can streamline development.
Future Evolution: Think about the potential future growth of your API. Will it need to integrate with diverse applications or remain within a controlled ecosystem? This can influence your decision towards interoperable REST or platform-specific RPC.
You’ll be well-equipped to select the best API design for your next project by carefully considering these elements in addition to the fundamental ideas mentioned above. This will guarantee effective communication and a solid basis for your application ecosystem.
Welcome to the exciting world of code! Whether you’re a budding programmer, a tech enthusiast, or simply curious about the inner workings of software, GitHub is an invaluable platform for your learning journey.
This comprehensive guide will equip you with the knowledge and strategies to leverage GitHub as a powerful learning tool. We’ll delve into the core concepts, explore the functionalities that benefit learners, and provide actionable steps to get you started.
Demystifying the Basics: What is GitHub?
At its core, GitHub is a version control system (VCS) built specifically for software development projects. It allows developers to track changes made to code over time, collaborate with others, and share projects publicly or privately. Think of it as a giant online storage facility specifically designed for code, with functionalities that empower collaboration and learning.
Why is GitHub a Learning Powerhouse for Beginners?
Here’s why GitHub deserves a prominent spot in your learning arsenal:
A Treasure Trove of Open-source Projects: GitHub is brimming with open-source projects, essentially free software that anyone can access, modify, and contribute to. This vast library provides you with a wealth of real-world code examples, allowing you to explore different programming languages, frameworks, and project structures.
Learning by Doing: The beauty of GitHub lies in its interactive nature. You can not only observe code but also actively participate by forking repositories (creating your own copy) and experimenting with changes. This hands-on approach solidifies your understanding and fosters practical coding skills.
Collaboration and Community: GitHub fosters a vibrant developer community. You can connect with experienced programmers, ask questions on project discussions, and contribute to discussions. This collaborative environment provides invaluable learning opportunities and insights from the broader developer network.
Version Control Mastery: Version control is a fundamental skill for any developer. GitHub’s intuitive interface allows you to grasp version control concepts like commits, branches, and merging in a practical way. Mastering these skills will enhance your future coding endeavors.
Building a Portfolio: As you learn and contribute to open-source projects, you can showcase your work on your GitHub profile. This serves as a growing portfolio, demonstrating your coding skills and project involvement to potential employers or collaborators.
Equipping Yourself for the Journey: Setting Up Your GitHub Account
Getting started with GitHub is a breeze. Head over to https://github.com/ and create a free account. You’ll be presented with a user-friendly interface that guides you through the initial steps.
Here are some key things to remember:
Choose a Descriptive Username: Your username is your identity on GitHub. Select a name that reflects your interests or coding aspirations.
Craft a Compelling Bio: Briefly introduce yourself, your skillset, and what you hope to achieve on GitHub.
Explore the Interface: Familiarize yourself with the dashboard, navigation bar, and search functionality. Explore the different sections like repositories, pull requests, and issues.
Learning by Observing: Exploring Open-source Projects
Now comes the fun part: delving into the world of open-source projects. Here’s how to make the most of this treasure trove:
Finding Projects: Utilize the search bar to find projects related to your learning goals. Browse by programming language, topic, or popularity.
Start with Beginner-friendly Projects: Don’t be intimidated! Look for projects specifically tagged as “beginner-friendly” or “first contribution welcome.” These projects offer clear documentation and a supportive community.
Readme Files are Your Friend: Most repositories have a “Readme” file outlining the project’s purpose, installation instructions, and contribution guidelines. This is your starting point for understanding the project.
Dive into the Code: Don’t be afraid to browse the codebase! Start with the main files and gradually explore different components. Look for comments within the code to understand the logic behind specific sections.
Taking it Up a Notch: Contributing to Open-source Projects
Once you feel comfortable with a project, consider contributing! Here’s how to make a positive impact:
Identify Issues: Many projects have an “Issues” section where developers list bugs, feature requests, or areas for improvement. Look for issues tagged as “good first issue” or “help wanted.”
Forking a Repository: Forking creates a copy of the original repository on your GitHub account. This allows you to make changes without affecting the main project.
Creating a Pull Request: Once you’ve made your contribution (e.g., fixing a bug), create a pull request. This proposes your changes to the original project’s maintainers for review and potential merging.
Embrace Feedback: Contributing is a learning experience in itself. Project maintainers will review your pull request and provide feedback. Don’t be discouraged by critiques; view them as opportunities to improve your coding skills and understand best practices.
Beyond the Basics: Advanced Learning Strategies with GitHub
As your confidence grows, explore these advanced learning strategies to maximize your GitHub experience:
Following Interesting Users and Organizations: Discover inspiring developers and organizations by following their profiles. You’ll stay updated on their projects, gain insights from their discussions, and potentially find collaboration opportunities.
Starring Repositories: “Starring” a repository signifies that you find it valuable or interesting. Use this feature to curate a personalized collection of learning resources for future reference.
Participating in Discussions: Don’t be a passive observer! Engage in discussions on projects you’re interested in. Ask questions, share your learnings, and contribute to the collaborative spirit of GitHub.
Leveraging GitHub Learning Lab: Explore the official GitHub Learning Lab (https://github.com/Wahl-lab/EXPLORE), a platform offering interactive courses and tutorials specifically designed to help you learn Git and GitHub functionalities.
Branching Out with Git Commands: While the GitHub interface simplifies version control, understanding the underlying Git commands empowers you for more complex workflows. There are numerous online resources and tutorials available to guide you through mastering Git commands.
Building Your Brand: Showcasing Your Work on GitHub
GitHub is more than just a learning platform; it’s a valuable tool for building your developer brand. Here’s how to make the most of it:
Maintaining an Active Profile: Regularly contribute to discussions, participate in projects, and showcase your learning journey. This demonstrates your passion for coding and keeps your profile fresh.
Creating Your Own Repositories: As you gain experience, consider creating your own projects and hosting them on GitHub. This allows you to showcase your coding skills and problem-solving abilities to potential employers or collaborators.
Curating Your Contributions: Not all contributions are equal. Highlight your most significant contributions in your profile’s “Readme” section or create a dedicated portfolio website to showcase your best work.
Conclusion: GitHub – Your Gateway to a Fulfilling Coding Journey
GitHub is an invaluable resource for anyone embarking on a coding adventure. By leveraging its functionalities strategically, you can transform it into a powerful learning tool. Remember, the key lies in consistent exploration, active participation, and a willingness to learn from the vast developer community. Embrace the challenges, celebrate your achievements, and watch yourself evolve into a confident and skilled programmer.
This guide has equipped you with the essential knowledge and strategies to get started. Now, it’s your turn to embark on your exciting learning journey on GitHub!
Normalisation is essential to database administration because it guarantees data economy, scalability, and integrity. Database Normal Forms are a collection of guidelines that control how data is arranged in relational databases to maximise efficiency and reduce dependencies and redundancies. From First Normal Form (1NF) to Sixth Normal Form (6NF), we shall examine the nuances of each Normal Form in this article, including thorough justifications and instructive examples.
First Normal Form (1NF)
The First Normal Form (1NF) is the fundamental building block of database normalization. To meet the requirements of 1NF, a relation must have:
Atomic Values: Each attribute or field within a relation must hold atomic values, meaning they cannot be further divided.
Unique Column Names: Every column in a relation must have a unique name to avoid ambiguity.
No Duplicate Rows: Each row in a relation must be unique, with no duplicate tuples.
Example:
Consider the following table representing student information:
Student_ID
Name
Courses
001
John
Math, Physics
002
Alice
Chemistry, Math
003
Bob
Physics, Biology
To convert this table into 1NF, we need to ensure atomicity and eliminate repeating groups. One way to achieve this is by creating separate rows for each course taken by a student:
Student_ID
Name
Course
001
John
Math
001
John
Physics
002
Alice
Chemistry
002
Alice
Math
003
Bob
Physics
003
Bob
Biology
Second Normal Form (2NF)
Second Normal Form (2NF) builds upon 1NF by addressing partial dependencies within relations. A relation is in 2NF if it meets the following criteria:
It is in 1NF.
All non-key attributes are fully functionally dependent on the primary key.
Example:
Consider a table that records orders and their corresponding products:
Order_ID
Product_ID
Product_Name
Unit_Price
1001
001
Laptop
$800
1001
002
Mouse
$20
1002
001
Laptop
$800
1003
003
Keyboard
$50
In this table, Order_ID serves as the primary key, and Product_ID is a partial key. To achieve 2NF, we need to separate the product information into a separate table:
Third Normal Form (3NF)
Third Normal Form (3NF) further refines the normalization process by eliminating transitive dependencies. A relation is in 3NF if it satisfies the following conditions:
It is in 2NF.
There are no transitive dependencies; that is, no non-key attribute depends on another non-key attribute.
Example:
Consider a table that stores information about employees, including their department and location:
Employee_ID
Employee_Name
Department
Location
001
John
Marketing
New York
002
Alice
HR
Los Angeles
003
Bob
Marketing
New York
In this table, both Department and Location are non-key attributes. However, Location depends on Department, creating a transitive dependency. To normalize this table to 3NF, we split it into two:
Boyce-Codd Normal Form (BCNF)
Boyce-Codd Normal Form (BCNF) is an extension of 3NF, addressing certain anomalies that may arise in relations with multiple candidate keys. A relation is in BCNF if, for every non-trivial functional dependency X → Y, X is a superkey.
Example:
Consider a table representing courses and their instructors:
Course_ID
Instructor_ID
Instructor_Name
Course_Name
001
101
John
Math
002
102
Alice
Physics
001
103
Bob
Math
In this table, {Course_ID, Instructor_ID} is a composite primary key. However, Instructor_Name depends only on Instructor_ID, violating BCNF. To normalize this table, we separate the Instructor information:
Fifth Normal Form (5NF)
Fifth Normal Form (5NF), also known as Project-Join Normal Form (PJNF), addresses multi-valued dependencies within relations. A relation is in 5NF if it satisfies the following conditions:
It is in 4NF.
All join dependencies are implied by the candidate keys.
Example:
Consider a table that represents the relationship between authors and their published books:
Author_ID
Book_ID
Author_Name
Book_Title
101
001
John
Book1
101
002
John
Book2
102
001
Alice
Book1
103
003
Bob
Book3
In this table, {Author_ID, Book_ID} forms a composite primary key. However, there is a multi-valued dependency between Author_ID and Book_Title. To normalize this table to 5NF, we split it into two:
Sixth Normal Form (6NF)
Sixth Normal Form (6NF), also known as Domain-Key Normal Form (DK/NF), deals with cases where dependencies exist between attributes and subsets of the keys. A relation is in 6NF if it meets the following criteria:
It is in 5NF.
There are no non-trivial join dependencies involving subsets of the candidate keys.
Example:
Consider a table representing sales data for products:
Product_ID
Product_Name
Region
Sales
001
Laptop
East
$500
001
Laptop
West
$700
002
Mouse
East
$100
002
Mouse
West
$150
In this table, {Product_ID, Region} is a composite key. However, there is a non-trivial join dependency between Region and Sales, as Sales depend only on Region. To normalize this table to 6NF, we separate the Region and Sales information.
Conclusion
To sum up, database normalisation is an essential step in creating relational databases that are effective and easy to maintain. Database designers can minimise redundancy, stop data abnormalities, and improve query efficiency by following the guidelines of Normal Forms. Comprehending and utilising the many Normal Forms, ranging from 1NF to 6NF, equips database experts to develop resilient and expandable database structures that satisfy the dynamic requirements of contemporary applications.
Ensuring accessibility is now a need in the field of software development, not merely a nice-to-have feature. Developers now have strong support at their disposal to improve accessibility of their codebase and expedite coding processes thanks to tools like Microsoft Copilot. We’ll explore how Microsoft Copilot can offer advice on how to optimise code for accessibility in this post, enabling developers to produce inclusive and user-friendly apps.
Understanding Microsoft Copilot
Microsoft Copilot is an AI-powered code completion tool built on OpenAI’s GPT technology. It operates as an extension for popular integrated development environments (IDEs) like Visual Studio Code, providing intelligent suggestions and snippets based on context and natural language input. By analyzing existing codebases and understanding programming patterns, Copilot assists developers in writing code more efficiently and effectively.
Importance of Accessibility in Code
Accessibility in software development refers to designing and coding applications in a way that ensures equal access and usability for individuals with disabilities. This includes considerations for users with visual, auditory, motor, or cognitive impairments. Making code accessible not only fosters inclusivity but also enhances usability for all users, leading to a better overall user experience.
Leveraging Microsoft Copilot for Accessibility Optimization
Microsoft Copilot can play a crucial role in optimizing code for accessibility by providing intelligent suggestions and insights tailored to accessibility best practices. Here’s how developers can leverage Copilot to enhance the accessibility of their code:
1. Semantic HTML Generation
Copilot can assist in generating semantic HTML markup, which is essential for creating accessible web applications. By suggesting appropriate HTML elements and attributes, Copilot helps developers ensure that content is properly structured and navigable for assistive technologies like screen readers.
2. Alt Text Recommendations
One of the fundamental principles of web accessibility is providing descriptive alternative text (alt text) for images. Copilot can offer suggestions for writing meaningful alt text that accurately describes the content and purpose of images, improving accessibility for users who rely on screen readers to access visual content.
3. Keyboard Navigation Enhancements
Keyboard navigation is essential for users who cannot use a mouse or other pointing devices. Copilot can provide guidance on implementing keyboard navigation shortcuts and ensuring that interactive elements are accessible via keyboard input, thus enhancing the usability of web applications for individuals with motor disabilities.
4. Contrast Ratio Optimization
Ensuring sufficient color contrast is crucial for users with visual impairments or color vision deficiencies. Copilot can suggest color combinations that meet accessibility standards, helping developers create designs that are legible and perceivable by all users, regardless of their visual abilities.
5. Accessible Form Controls
Forms are a common element in web applications, and making form controls accessible is essential for users with disabilities. Copilot can provide recommendations for implementing accessible form controls, such as using appropriate labels, providing error messages, and ensuring focus management for keyboard users.
6. ARIA Roles and Attributes
The Accessible Rich Internet Applications (ARIA) specification provides additional semantics to web content, making it more accessible to assistive technologies. Copilot can offer suggestions for using ARIA roles and attributes to enhance the accessibility of dynamic web interfaces, such as modal dialogs, tabs, and live regions.
Conclusion
When it comes to helping developers optimise their code for accessibility, Microsoft Copilot is a formidable ally. Developers may make sure that their applications are inclusive and accessible to users of all abilities by utilising Copilot’s insightful ideas and insights. Copilot enables developers to easily incorporate accessibility best practices into their coding workflow by generating semantic HTML, suggesting alt text, and improving keyboard navigation.
Tools like Microsoft Copilot will become more and more important as we prioritise accessibility in software development and work to create a more inclusive digital environment. By using Copilot’s accessibility optimisation, developers may help create a more equal and accessible online environment for all users.
In the current digital era, network security is crucial as cybercriminals may be found everywhere on the internet. A firewall is an essential part of any strong cybersecurity plan. We’ll examine the importance of firewalls, their various varieties, their operation, and best practices for their efficient implementation in this post.
Introduction to Firewalls
The security of computer networks has become a critical issue in today’s linked world, as organisations and individuals mostly rely on digital technology for information sharing, trade, and communication. The first line of defence against the numerous cyberthreats that are always scouring the internet is a firewall.
A firewall might be thought of as a watchful guard at the entrance to your company’s internal network, standing guard over the vast internet. Similar to a border control official checking passports at an international airport, its main job is to monitor and manage the flow of traffic into and out of your network.
But unlike human border agents, firewalls operate at lightning speed, analyzing data packets in real-time as they traverse the network infrastructure. By employing a combination of predetermined rules, algorithms, and intelligent filtering mechanisms, firewalls determine which packets are permitted to pass through and which are blocked, effectively safeguarding your network from malicious intruders.
The metaphorical “wall” in firewall symbolizes the barrier it erects between your trusted internal network and the untrusted external world of the internet. This barrier is essential for maintaining the integrity, confidentiality, and availability of your network resources, shielding them from a myriad of cyber threats such as malware infections, unauthorized access attempts, and data breaches.
Firewalls come in various forms, from basic packet filtering firewalls to advanced next-generation firewalls (NGFW) equipped with sophisticated intrusion detection and prevention capabilities. Regardless of their complexity, all firewalls share the common goal of fortifying your network defenses and thwarting cyber adversaries at every turn.
In essence, firewalls serve as the digital guardians of your network, tirelessly patrolling the digital perimeter, and standing vigilant against the ever-present specter of cyber threats. Understanding their role and importance in modern cybersecurity is crucial for organizations and individuals alike as they navigate the complex and dynamic landscape of cyberspace.
Types of Firewalls
Firewalls come in various types, each offering unique functionalities and capabilities to protect your network from cyber threats. Understanding the differences between these types can help you choose the most suitable firewall solution for your organization’s security needs.
1. Packet Filtering Firewalls
Packet filtering firewalls operate at the network layer (Layer 3) of the OSI model and make decisions based on individual packets of data as they pass through the firewall. These firewalls examine the header information of each packet, including source and destination IP addresses, port numbers, and protocol types, and compare them against predefined rules or access control lists (ACLs).
Packet filtering firewalls are relatively simple and efficient, making them well-suited for high-speed network environments. However, they lack the ability to inspect the contents of data packets beyond the header information, which may limit their effectiveness in detecting and blocking certain types of threats, such as advanced malware or application-layer attacks.
2. Stateful Inspection Firewalls
Stateful inspection firewalls, also known as dynamic packet filtering firewalls, combine the functionalities of packet filtering with additional context-awareness. In addition to examining individual packets, these firewalls maintain a stateful connection table or state table that keeps track of the state of active network connections.
By correlating incoming packets with existing connection states, stateful inspection firewalls can make more informed decisions about whether to allow or block traffic. This approach enhances security by ensuring that only legitimate packets associated with established connections are permitted, while unauthorized or potentially malicious packets are blocked.
Stateful inspection firewalls offer improved security and performance compared to traditional packet filtering firewalls, making them suitable for a wide range of network environments, including enterprise networks and high-traffic internet gateways.
3. Proxy Firewalls
Proxy firewalls, also known as application-level gateways (ALGs), operate at the application layer (Layer 7) of the OSI model and provide enhanced security by acting as intermediaries between internal and external network connections. Instead of allowing direct communication between network endpoints, proxy firewalls establish separate connections for incoming and outgoing traffic, effectively hiding the true network addresses of internal systems.
When a client initiates a connection to an external server, the proxy firewall intercepts the request, establishes a connection on behalf of the client, and forwards the request to the destination server. Similarly, incoming traffic from external sources is routed through the proxy firewall, which inspects the data for malicious content before forwarding it to internal systems.
Proxy firewalls offer granular control over network traffic and application-level protocols, allowing organizations to enforce strict security policies and inspect content for threats such as malware, phishing attempts, and unauthorized access attempts. However, they may introduce additional latency and complexity to network communications due to the need for packet inspection and processing.
4. Next-Generation Firewalls (NGFW)
Next-generation firewalls (NGFWs) represent the evolution of traditional firewall technologies, incorporating advanced security features and capabilities to address the changing threat landscape. In addition to the core functionalities of packet filtering and stateful inspection, NGFWs offer:
Intrusion Detection and Prevention System (IDPS): NGFWs can detect and block known and unknown threats by analyzing network traffic for signs of malicious activity, such as signature-based and behavior-based intrusion detection and prevention.
Application Awareness: NGFWs provide deep packet inspection capabilities to identify and control applications and protocols traversing the network, enabling granular control over application usage and access policies.
Advanced Threat Protection: NGFWs integrate threat intelligence feeds, sandboxing, and other advanced security technologies to detect and mitigate sophisticated threats such as zero-day exploits, advanced malware, and targeted attacks.
Centralized Management and Reporting: NGFWs offer centralized management consoles and reporting tools that provide administrators with visibility into network activity, security events, and policy compliance across distributed environments.
NGFWs are designed to provide comprehensive protection against a wide range of cyber threats, making them ideal for organizations seeking advanced security capabilities and unified threat management (UTM) solutions.
In summary, firewalls play a critical role in safeguarding networks from cyber threats by controlling and monitoring network traffic. Whether you opt for a traditional packet filtering firewall, a stateful inspection firewall, a proxy firewall, or a next-generation firewall, choosing the right type of firewall depends on your organization’s security requirements, network architecture, and budget considerations.
How Firewalls Work
Firewalls are the guardians of your network, standing as the first line of defense against cyber threats. Understanding how firewalls work is essential for comprehending their role in safeguarding your digital infrastructure.
OSI Model Layers
Firewalls operate at different layers of the OSI (Open Systems Interconnection) model, each serving a specific purpose in analyzing and controlling network traffic:
Network Layer (Layer 3): At this layer, firewalls primarily employ packet filtering techniques to inspect individual data packets based on criteria such as IP addresses, port numbers, and protocols. Packets that meet the predefined rules are allowed to pass through, while those that violate the rules are discarded.
Transport Layer (Layer 4): Firewalls can also operate at the transport layer, where they examine transport layer protocols such as TCP (Transmission Control Protocol) and UDP (User Datagram Protocol). Stateful inspection firewalls, in particular, keep track of the state of active connections by maintaining session information, enabling them to make more informed decisions about which packets to permit or deny.
Application Layer (Layer 7): Some advanced firewalls extend their capabilities to the application layer, where they inspect and filter traffic based on specific applications or services. This deep packet inspection allows firewalls to identify and block potentially malicious content embedded within application-layer protocols.
Packet Filtering
Packet filtering is the fundamental mechanism employed by firewalls to regulate the flow of network traffic. When a data packet traverses the firewall, it undergoes scrutiny based on predefined rules configured by network administrators. These rules dictate which packets are permitted to pass through the firewall and which are blocked.
Packet filtering can be implemented using either “allow-list” or “deny-list” approaches. In the allow-list approach, only packets matching explicitly defined criteria are permitted, while in the deny-list approach, packets matching specific criteria are explicitly blocked.
Stateful Inspection
Stateful inspection, also known as dynamic packet filtering, enhances the security capabilities of firewalls by considering the context of network connections. Unlike traditional packet filtering, which evaluates each packet in isolation, stateful inspection firewalls maintain information about the state of active connections.
By keeping track of established connections, including session information such as source and destination IP addresses, port numbers, and sequence numbers, stateful inspection firewalls can make more nuanced decisions about which packets to permit or deny. This approach reduces the likelihood of malicious activities such as IP spoofing and session hijacking.
Deep Packet Inspection
Deep packet inspection (DPI) is an advanced inspection technique that enables firewalls to scrutinize the contents of data packets at a granular level. Unlike traditional packet filtering, which focuses on header information, DPI delves into the payload of packets to identify specific patterns, signatures, or anomalies indicative of malicious behavior.
By analyzing the content of packets, including application-layer protocols and payload data, DPI-capable firewalls can detect and block sophisticated threats such as malware, exploits, and command-and-control communications. This level of scrutiny is particularly valuable in defending against targeted attacks and emerging threats that evade traditional security measures.
In summary, firewalls employ a combination of packet filtering, stateful inspection, and deep packet inspection techniques to analyze and control network traffic. By operating at different layers of the OSI model and employing varying inspection methods, firewalls provide comprehensive protection against a wide range of cyber threats. Understanding how firewalls work is essential for designing effective security policies and implementing robust cybersecurity defenses.
Importance of Firewalls in Cybersecurity
With the proliferation of cyber threats ranging from malware and ransomware to phishing attacks, firewalls play a pivotal role in protecting sensitive data and thwarting unauthorized access attempts. By implementing robust firewall policies, organizations can mitigate the risk of data breaches and ensure the confidentiality, integrity, and availability of their network resources.
Advantages of Using Firewalls
Firewalls offer a multitude of advantages in enhancing network security and protecting against cyber threats. From controlling access to filtering malicious content, their importance cannot be overstated in today’s interconnected digital landscape.
1. Enhanced Network Security
One of the primary advantages of using firewalls is the bolstering of network security. By establishing a barrier between internal networks and external entities, firewalls prevent unauthorized access attempts and malicious intrusions. With the ability to enforce access control policies and filter incoming and outgoing traffic, firewalls significantly reduce the risk of security breaches and safeguard sensitive data.
2. Protection Against Cyber Threats
In the face of evolving cyber threats such as malware, ransomware, and phishing attacks, firewalls serve as a crucial line of defense. By inspecting network traffic and identifying potentially harmful content, firewalls can block malicious activities before they can inflict damage. This proactive approach to threat mitigation helps organizations stay ahead of cyber adversaries and mitigate the impact of cyberattacks.
3. Granular Access Control
Firewalls enable organizations to implement granular access control policies, allowing them to regulate the flow of traffic based on predefined criteria. By defining rules and permissions for different users, devices, and applications, organizations can ensure that only authorized entities can access specific network resources. This level of granularity enhances security posture and minimizes the risk of unauthorized access to sensitive data.
4. Traffic Filtering Capabilities
Another significant advantage of firewalls is their ability to filter incoming and outgoing traffic, thereby blocking malicious content and preventing potential security threats. By inspecting data packets and applying predefined rules, firewalls can identify and quarantine suspicious activities, such as suspicious URLs, malware downloads, or unauthorized access attempts. This proactive approach to traffic filtering helps organizations maintain the integrity of their network environment and protect against a wide range of cyber threats.
5. Network Segmentation
Firewalls facilitate network segmentation by dividing the network into distinct zones or segments, each with its own set of security policies and controls. This segmentation helps organizations contain security breaches and limit the impact of potential cyberattacks. By isolating sensitive data and critical resources from less secure areas of the network, firewalls minimize the risk of lateral movement by cyber adversaries and mitigate the spread of malware or other malicious activities.
6. Regulatory Compliance
For organizations operating in regulated industries such as finance, healthcare, or government, compliance with industry-specific regulations and standards is paramount. Firewalls play a crucial role in helping organizations achieve regulatory compliance by enforcing security controls, protecting sensitive data, and maintaining audit trails of network activities. By demonstrating adherence to regulatory requirements, organizations can avoid costly penalties, reputational damage, and legal ramifications.
7. Scalability and Flexibility
Modern firewalls offer scalability and flexibility to adapt to evolving security needs and changing network environments. Whether deployed as hardware appliances, software solutions, or cloud-based services, firewalls can be tailored to suit the unique requirements of organizations of all sizes and industries. With features such as centralized management, automated updates, and customizable rule sets, firewalls empower organizations to optimize their security posture and adapt to emerging threats effectively.
In conclusion, firewalls provide a robust and versatile solution for enhancing network security, protecting against cyber threats, and ensuring regulatory compliance. By leveraging the advantages of firewalls, organizations can establish a strong cybersecurity posture, mitigate the risk of security breaches, and safeguard their digital assets in today’s dynamic threat landscape.
Best Practices for Firewall Implementation
Implementing a firewall is a critical step in fortifying your organization’s cybersecurity posture. However, deploying a firewall alone is not sufficient; it must be configured and managed effectively to maximize its effectiveness in protecting your network. Here are some best practices for firewall implementation:
1. Conduct a Comprehensive Risk Assessment
Before deploying a firewall, conduct a thorough risk assessment to identify potential security vulnerabilities, threats, and compliance requirements specific to your organization. Understanding your risk landscape will help you tailor firewall rules and policies to address your most pressing security concerns effectively.
2. Define Clear Firewall Rules and Policies
Establish clear and comprehensive firewall rules and policies that align with your organization’s security objectives, regulatory requirements, and business needs. Clearly define which types of traffic are permitted, denied, or restricted based on factors such as source and destination IP addresses, ports, protocols, and application types.
3. Implement a Least Privilege Approach
Adopt a least privilege approach when configuring firewall rules, granting only the minimum level of access necessary for users and systems to perform their intended functions. Limiting unnecessary network traffic reduces the attack surface and minimizes the risk of unauthorized access and potential security breaches.
4. Regularly Update Firewall Software and Signatures
Keep your firewall software and threat signatures up to date with the latest patches and updates provided by the vendor. Regularly updating your firewall ensures that it remains resilient against emerging threats, vulnerabilities, and exploits, helping to maintain the integrity of your network defenses.
5. Enable Logging and Monitoring Features
Enable logging and monitoring features on your firewall to capture and analyze network traffic, security events, and policy violations in real-time. By monitoring firewall logs, you can identify suspicious activities, unauthorized access attempts, and potential security incidents promptly, allowing for timely detection and response.
6. Establish Redundancy and Failover Mechanisms
Implement redundancy and failover mechanisms to ensure continuous availability and reliability of your firewall infrastructure. Deploying redundant firewalls in high-availability configurations helps mitigate the risk of downtime due to hardware failures, software crashes, or network outages, maintaining uninterrupted protection for your network assets.
7. Regularly Review and Update Firewall Rules
Periodically review and update firewall rules to reflect changes in your organization’s network infrastructure, security policies, and compliance requirements. Remove obsolete rules, fine-tune rule configurations, and adjust access controls as needed to adapt to evolving threats and business needs effectively.
8. Test Firewall Configurations and Rule Sets
Conduct regular testing and validation of firewall configurations and rule sets to ensure their effectiveness and compliance with security policies. Perform penetration testing, vulnerability assessments, and firewall rule audits to identify gaps, misconfigurations, and potential security weaknesses that could be exploited by malicious actors.
9. Integrate Firewalls with Security Frameworks
Integrate firewalls with other cybersecurity solutions such as intrusion detection systems (IDS), intrusion prevention systems (IPS), and security information and event management (SIEM) platforms for enhanced threat detection, incident response, and forensic analysis capabilities. By sharing threat intelligence and coordinating defense mechanisms, integrated security frameworks provide a more comprehensive defense against advanced cyber threats.
10. Provide Ongoing Training and Awareness
Educate employees, IT staff, and stakeholders about the importance of firewall security, best practices for configuring and managing firewalls, and their role in protecting sensitive information and assets. Foster a culture of cybersecurity awareness and accountability throughout your organization to mitigate the risk of human error and insider threats.
By following these best practices for firewall implementation, organizations can strengthen their cybersecurity defenses, reduce the risk of data breaches and cyber attacks, and safeguard the integrity and confidentiality of their network infrastructure and digital assets.
Remember, effective firewall management is not a one-time task but an ongoing process that requires vigilance, proactive monitoring, and continuous improvement to adapt to the evolving threat landscape and ensure optimal protection against cyber threats.
Conclusion
To sum up, firewalls are the mainstay of contemporary cybersecurity infrastructure, protecting networks from a variety of online attacks. Installing firewalls is crucial for safeguarding your digital assets and preserving the integrity of your network environment, regardless of the size of your company. Through comprehension of the many kinds of firewalls, their functions, and optimal approaches for their deployment, establishments can reinforce their safeguards and maintain a competitive edge over cyber threats.
In today’s linked world, putting in place a strong firewall strategy is not only a recommended practice, but a vital requirement.
Always remember that firewalls are your first line of defence against online hackers and that prevention is always preferable to treatment when it comes to cybersecurity.
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
}
Step 5: Gradle Configuration
Ensure you have the necessary dependencies in your build.gradle file:
// build.gradle
plugins {
id 'org.springframework.boot' version '2.6.3'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id 'java'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '11'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-security'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'mysql:mysql-connector-java'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-validation'
implementation 'org.springframework.boot:spring-boot-starter-websocket'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
test {
useJUnitPlatform()
}
Step 6: Running the Application
You can run the application using Gradle with the following command:
./gradlew bootRun
Now, your Spring Boot application with JDBC authentication is ready to use!
Conclusion
In this tutorial, you’ve learned how to set up Spring Boot Security with JDBC authentication. You configured the database, created necessary tables, and defined Spring Security configurations to authenticate users using JDBC. Feel free to expand on this foundation to add more features and customize the security aspects of your application.