Introduction
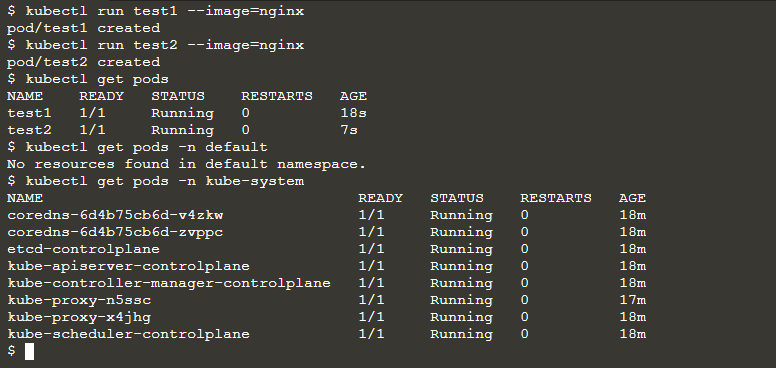
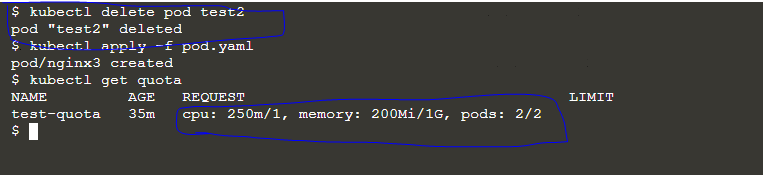
It can be difficult to manage and orchestrate containers across a distributed infrastructure in the world of containerization and cloud computing. A simple and scalable method for deploying, scaling, and managing containers across multiple hosts is provided by Docker Swarm, a native clustering and orchestration solution from Docker.
This article explores the fundamentals of Docker Swarm, its key features, and why it has become a popular choice for container orchestration.
What is Docker Swarm?
Docker Swarm is a native clustering and orchestration solution provided by Docker. It allows users to create and manage a swarm of Docker nodes, effectively turning them into a single, virtual Docker host. This enables the deployment and management of containerized applications across a distributed infrastructure.
At its core, Docker Swarm is designed to simplify the process of container orchestration. It provides a straightforward and scalable approach to deploying and scaling containers, making it easier to manage large-scale containerized environments. With Docker Swarm, organizations can effectively utilize the benefits of containerization while ensuring high availability, load balancing, and fault tolerance.
Docker Swarm operates using a manager-worker architecture. The swarm manager is responsible for orchestrating the cluster, managing the workload distribution, and maintaining the desired state of the services running within the swarm. The worker nodes are the hosts where containers are deployed and run.
One of the key features of Docker Swarm is its ability to scale applications seamlessly. By adding or removing worker nodes from the swarm, the cluster can dynamically adapt to changing workloads. This scalability ensures that resources are efficiently utilized and applications can handle increased demand without compromising performance.
Docker Swarm also provides built-in service discovery, allowing containers within the swarm to communicate with each other seamlessly. Each service within the swarm is assigned a unique hostname and virtual IP address, simplifying the process of connecting and interacting between containers.
Load balancing is another important feature of Docker Swarm. It includes an integrated load balancer that evenly distributes incoming requests across multiple containers running the same service. This load balancing mechanism helps optimize resource utilization and ensures that the workload is evenly distributed across the swarm.
Docker Swarm incorporates self-healing capabilities to maintain the desired state of services. It continuously monitors the health of containers and nodes within the swarm. If a container or node fails, Swarm automatically restarts or reschedules the affected containers on healthy nodes, ensuring that services remain available and responsive.
Security is a key concern in containerized environments, and Docker Swarm addresses this by providing built-in security features. It supports mutual TLS authentication and encryption for secure communication between nodes. Additionally, role-based access control (RBAC) allows administrators to manage user permissions and access to swarm resources.
Key Features of Docker Swarm
There are several reasons why you might choose Docker Swarm as your container orchestration solution. Here are some key advantages of Docker Swarm:
Easy Setup and Integration: Docker Swarm is part of the Docker ecosystem, which means it can be easily set up using Docker Engine. If you’re already familiar with Docker, the learning curve for Docker Swarm is relatively low. It seamlessly integrates with other Docker tools and services, making it a natural choice if you’re already using Docker containers.
Simplicity: Docker Swarm focuses on simplicity and ease of use. It offers a user-friendly command-line interface and a straightforward API, making it accessible to developers and operators with varying levels of expertise. Docker Swarm’s simplicity reduces the complexity of managing and orchestrating containers, enabling you to focus more on your applications rather than the infrastructure.
Scalability and High Availability: Docker Swarm allows you to easily scale your applications by adding or removing worker nodes from the swarm. It provides a distributed and scalable architecture to handle increasing workloads. Docker Swarm’s built-in load balancing feature ensures efficient resource utilization and improves the availability and performance of your applications. In case of node failures, Swarm automatically redistributes containers to healthy nodes, ensuring high availability.
Service Discovery and Networking: Docker Swarm includes a built-in service discovery mechanism. Each service within the swarm is assigned a unique hostname and virtual IP address, making it easy for containers to communicate with each other. Swarm’s networking capabilities simplify the connectivity between containers and enable seamless interaction within the swarm.
Rolling Updates and Rollbacks: Docker Swarm supports rolling updates, allowing you to deploy new versions of containers without disrupting the availability of your application. It automatically updates containers one by one, ensuring that the service remains accessible during the update process. If an issue arises, Swarm facilitates easy rollbacks to previous versions, minimizing downtime and maintaining application stability.
Security: Docker Swarm provides built-in security features to protect your containerized applications. It supports mutual TLS authentication and encryption for secure communication between nodes. Role-based access control (RBAC) allows you to manage user permissions and restrict access to swarm resources, ensuring that your cluster is secure by default.
Flexibility: Docker Swarm is a flexible orchestration solution that can be used for a wide range of applications, from small-scale deployments to large-scale clusters. It provides a balance between ease of use and the ability to handle complex containerized environments. With Docker Swarm, you have the flexibility to scale and adapt your infrastructure as your requirements evolve.
Key Components of Docker Swarm
Docker Swarm consists of several key components that work together to enable container orchestration and management within a swarm. These components include:
Swarm Manager: The Swarm Manager is responsible for managing the overall swarm and its resources. It coordinates the activities of worker nodes, schedules tasks, and maintains the desired state of the services running within the swarm. The manager also handles service discovery, load balancing, and failure recovery.
Worker Nodes: Worker nodes are the hosts where containers are deployed and run. These nodes participate in the swarm and execute tasks assigned by the Swarm Manager. Worker nodes provide the computing resources required to run containers and scale services as per demand.
Service: In Docker Swarm, a service represents a group of containers that perform the same function or run the same application. A service defines the desired state of the containers, such as the number of replicas, container image, networking configuration, and resource constraints. The Swarm Manager ensures that the desired state is maintained by continuously monitoring and managing the service.
Task: A task represents a single instance of a container running on a worker node. The Swarm Manager assigns tasks to worker nodes based on the defined service specifications. It also monitors the health of tasks and takes necessary actions to maintain the desired state, such as restarting failed tasks or rescheduling them on other healthy nodes.
Overlay Network: An overlay network is a virtual network that spans across multiple worker nodes in the swarm. It facilitates communication between containers running on different nodes, regardless of their physical network location. The overlay network allows containers within the swarm to discover and communicate with each other using their service names.
Load Balancer: Docker Swarm includes an inbuilt load balancer that distributes incoming requests across multiple containers running the same service. The load balancer ensures even distribution of traffic and optimizes resource utilization. It directs requests to healthy containers, providing high availability and scalability for the services.
Swarm Visualizer (Optional): Swarm Visualizer is an optional component that provides a visual representation of the swarm’s architecture and the containers running within it. It offers a graphical interface to monitor and track the status of services, tasks, and nodes in real-time.
These components work together to create a robust and scalable environment for deploying and managing containerized applications. The Swarm Manager oversees the swarm’s operations, worker nodes execute tasks, services define the desired state of containers, tasks represent running containers, and overlay networks facilitate communication between containers. The load balancer ensures efficient traffic distribution, and the optional Swarm Visualizer provides a visual representation of the swarm’s status.
Docker Swarm Success Stories
Docker Swarm has been widely adopted by various organizations for container orchestration and management. Here are a few success stories showcasing how Docker Swarm has helped businesses improve their infrastructure and streamline their operations:
PayPal: PayPal, a leading online payment platform, adopted Docker Swarm to enhance its infrastructure and improve application deployment. By leveraging Docker Swarm, PayPal achieved simplified container orchestration, scalability, and high availability for their microservices architecture. Docker Swarm allowed PayPal to efficiently manage their containerized applications across multiple hosts, enabling seamless scaling and reducing deployment complexities.
Société Générale: Société Générale, a major European financial services company, utilized Docker Swarm to modernize its IT infrastructure. Docker Swarm enabled them to containerize their applications and easily deploy them across their infrastructure. The high availability and fault-tolerant features of Docker Swarm allowed Société Générale to ensure continuous availability of their critical services, improving the resilience of their applications.
Schibsted: Schibsted, a Norwegian media conglomerate, adopted Docker Swarm to streamline their application deployment processes and achieve operational efficiency. With Docker Swarm, Schibsted was able to automate the deployment of their services and scale them according to demand. Docker Swarm’s built-in load balancing and service discovery mechanisms simplified their infrastructure management, leading to improved application performance and reduced time to market.
REWE Digital: REWE Digital, a leading German retail and e-commerce company, implemented Docker Swarm to optimize their infrastructure and facilitate the deployment of containerized applications. Docker Swarm provided them with a scalable and flexible platform to manage their services across multiple hosts. REWE Digital experienced improved resource utilization, simplified service scaling, and enhanced resilience of their applications using Docker Swarm.
Maersk Line: Maersk Line, the world’s largest container shipping company, leveraged Docker Swarm to modernize their IT infrastructure and streamline their application deployment processes. Docker Swarm enabled Maersk Line to manage and scale their containerized applications seamlessly across their global infrastructure. By adopting Docker Swarm, Maersk Line achieved faster deployment times, improved resource efficiency, and increased application availability.
These success stories highlight the benefits of Docker Swarm in simplifying container orchestration, enhancing scalability, improving availability, and optimizing resource utilization for various industries. Docker Swarm’s features and capabilities have empowered organizations to efficiently manage their containerized applications, resulting in enhanced operational efficiency, reduced infrastructure complexity, and accelerated application delivery.
Why Choose Docker Swarm?
Easy Setup: Docker Swarm is part of the Docker ecosystem, which means it can be easily set up using Docker Engine. The learning curve is relatively low, especially if you are already familiar with Docker.
Native Integration: Docker Swarm is a native solution provided by Docker, ensuring compatibility and seamless integration with other Docker tools and services. This makes it an excellent choice for organizations already using Docker containers.
Simplicity: Docker Swarm focuses on simplicity, offering a user-friendly command-line interface and a straightforward API. The simplicity of Swarm makes it accessible to developers and operators with varying levels of expertise.
Flexibility: Swarm is a flexible orchestration solution that can be used for a wide range of applications, from simple single-node deployments to large-scale multi-node clusters. It provides a balance between ease of use and the ability to handle complex containerized environments.
Challenges and Drawbacks of Using Docker Swarm
While Docker Swarm offers many advantages for container orchestration, there are some challenges and drawbacks to consider:
Learning Curve: Although Docker Swarm is designed to be user-friendly, there is still a learning curve involved in understanding its concepts, architecture, and command-line interface. Administrators and developers may need to invest time and effort in familiarizing themselves with Swarm’s specific features and functionalities.
Limited Features Compared to Kubernetes: While Docker Swarm provides essential container orchestration capabilities, it may not have the same level of advanced features and flexibility as Kubernetes. Kubernetes has a larger ecosystem and offers more advanced features for managing complex containerized environments, such as advanced networking, storage orchestration, and extensive customization options.
Scaling Limitations: Docker Swarm is suitable for small to medium-scale deployments, but it may face challenges in handling very large clusters or highly dynamic workloads. It has a scalability limit and may experience performance degradation or increased management complexity as the swarm size grows beyond a certain threshold.
Lack of Third-Party Integrations: Docker Swarm, compared to Kubernetes, may have limited third-party integrations and a smaller ecosystem of tools and services built around it. This could restrict the availability of specific plugins or extensions that organizations may require for their specific use cases.
Limited Maturity: Docker Swarm is not as mature as Kubernetes, which has been widely adopted and has a larger community contributing to its development and support. This could result in fewer resources, tutorials, and troubleshooting options available for Docker Swarm compared to Kubernetes.
Less Comprehensive Monitoring and Debugging: Docker Swarm’s monitoring and debugging capabilities are not as comprehensive as those provided by other orchestration platforms. While it offers basic monitoring features, organizations may need to rely on third-party tools or custom solutions to gain more advanced monitoring and debugging capabilities.
Limited Cluster Management: Docker Swarm’s cluster management capabilities are relatively basic compared to Kubernetes. It may lack certain advanced management features, such as fine-grained control over resource allocation, pod affinity/anti-affinity rules, and more complex scheduling strategies.
It’s important to consider these challenges and drawbacks in relation to your specific requirements, the size of your deployment, and the complexity of your containerized applications. Evaluating alternative container orchestration solutions, such as Kubernetes, may be necessary to determine the best fit for your organization’s needs.
Conclusion
By offering an easy-to-use and scalable method for deploying and controlling a large number of containers, Docker Swarm makes container orchestration simpler. The key features of Docker Swarm, including scalability, service discovery, load balancing, and self-healing capabilities, make it simple for businesses to create and manage reliable containerized applications. Whether you are a small team or a large organization, Docker Swarm offers an adaptable and affordable way for you to take advantage of containerization’s power and effectively manage your distributed infrastructure.
In conclusion, the container orchestration tool Docker Swarm is strong and simple to use. Scalability, service discovery, load balancing, self-healing, and security are among the features that make it easier to deploy, scale, and manage containers across a distributed infrastructure. The widespread use of Docker Swarm is a result of its easy integration with other Docker tools and its effectiveness in managing both small- and large-scale containerized environments.
To sum up, Docker Swarm provides a strong set of features and advantages for container orchestration. For managing containerized applications, it is a popular option due to its simplicity, scalability, high availability, service discovery, rolling updates, security features, and flexibility. You can concentrate on delivering your applications with confidence whether you are a small team or a large organization because Docker Swarm makes the deployment and management of containers simple.




 initially
initially