
Introduction
Relational database design and organisation are based on the fundamental idea of database normalisation. Enhancing data integrity, lowering redundancy, and enabling effective data management are its main objectives. We will delve into the fundamentals of database normalisation, examine the normalisation procedure, talk about different forms and techniques of normalisation, and look at the function of denormalization in this extensive guide.
1. What is Database Normalization?
The process of arranging data in a relational database to reduce dependencies and redundancies is called database normalisation. It entails defining relationships between big tables and segmenting them into smaller, easier-to-manage entities. Eliminating data anomalies, preserving data integrity, and improving database performance are the main goals of normalisation.
Normalisation forms are a collection of guidelines and norms that serve as the foundation for database normalisation. These forms offer an organised method for arranging data and enhancing database performance. A well-organized and normalised data model that facilitates effective data storage, retrieval, and manipulation can be achieved by databases by following the normalisation principles.
2. The Normalization Process
The normalization process typically involves several stages, each focusing on a specific aspect of data organization and structure. These stages are represented by normalization forms, which define progressively stricter rules for data organization.
First Normal Form (1NF): The first normal form requires that each table cell contains a single value, and there are no repeating groups or arrays of data within a row. To achieve 1NF, tables are divided into rows and columns, and atomic values are ensured for each attribute.
Example:
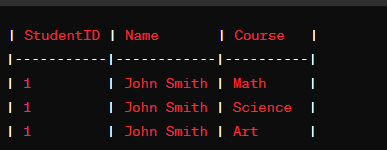
Consider a table for storing student information:

To convert this table to 1NF, we break the Courses column into atomic values:
Second Normal Form (2NF): The second normal form builds upon the first by eliminating partial dependencies. It requires that each non-key attribute is fully functionally dependent on the primary key. This is achieved by breaking down tables into smaller entities and ensuring that each attribute depends on the entire primary key, not just part of it.
Example:
Consider a table for storing orders and products:

To convert this table to 2NF, we break it into two tables: Orders and Products, with the primary key of Orders being OrderID and the primary key of Products being ProductID. We then remove redundant information from the Orders table:

Third Normal Form (3NF): The third normal form further refines the data structure by eliminating transitive dependencies. It requires that each non-key attribute is functionally dependent only on the primary key and not on other non-key attributes. This is accomplished by removing attributes that depend on other non-key attributes.
Example:
Consider a table for storing employee information:
Jane Doe |

To convert this table to 3NF, we remove the ManagerName attribute, as it is functionally dependent on ManagerID:

We then create a separate table for managers:
Jane Doe |

Boyce-Codd Normal Form (BCNF): BCNF is a stricter form of normalization that eliminates all non-trivial functional dependencies. It ensures that every determinant is a candidate key, thereby minimizing redundancy and dependency. Achieving BCNF may require decomposing tables into smaller entities and redefining relationships.
3. Functional Dependencies and Normalization Forms
Functional dependencies play a crucial role in the normalization process by defining the relationships between attributes in a table. A functional dependency exists when one attribute uniquely determines another attribute. By identifying and eliminating dependencies, databases can achieve higher levels of normalization and reduce data redundancy.
Normalization forms are based on specific rules and criteria for functional dependencies. Each normalization form addresses different types of dependencies and anomalies, guiding database designers in the process of organizing data effectively.
4. Common Normalization Techniques
While the normalization process aims to optimize database structure and integrity, it may sometimes lead to performance implications, such as increased join operations and query complexity. In such cases, denormalization techniques may be employed to balance performance and maintainability.
Denormalization: Denormalization involves reintroducing redundancy into a normalized database to improve query performance and simplify data retrieval. This may include duplicating data, introducing redundant indexes, or precalculating summary statistics. Denormalization should be approached cautiously to avoid compromising data integrity and consistency.
Partial Denormalization: Partial denormalization selectively introduces redundancy into specific areas of a database where performance improvements are most needed. This approach allows for a balance between normalization principles and performance considerations, providing flexibility in database design.
Horizontal and Vertical Denormalization: Horizontal denormalization involves splitting a table into multiple smaller tables to reduce data redundancy and improve performance. Vertical denormalization, on the other hand, involves combining multiple tables into a single table to simplify queries and reduce join operations.
5. Conclusion
A crucial component of relational database architecture, database normalisation seeks to reduce redundancy, enhance data integrity, and maximise database performance. Databases can create an effective and well-organized data model that satisfies the needs of contemporary applications by following normalisation forms and principles.
To sum up, building reliable and scalable databases requires an awareness of functional interdependence, database normalisation, and normalisation forms. Normalisation guarantees data organisation and integrity; performance concerns can be addressed by using denormalization techniques. Organisations may create robust, high-performance database systems that serve their business goals by finding a balance between normalisation and denormalization.









